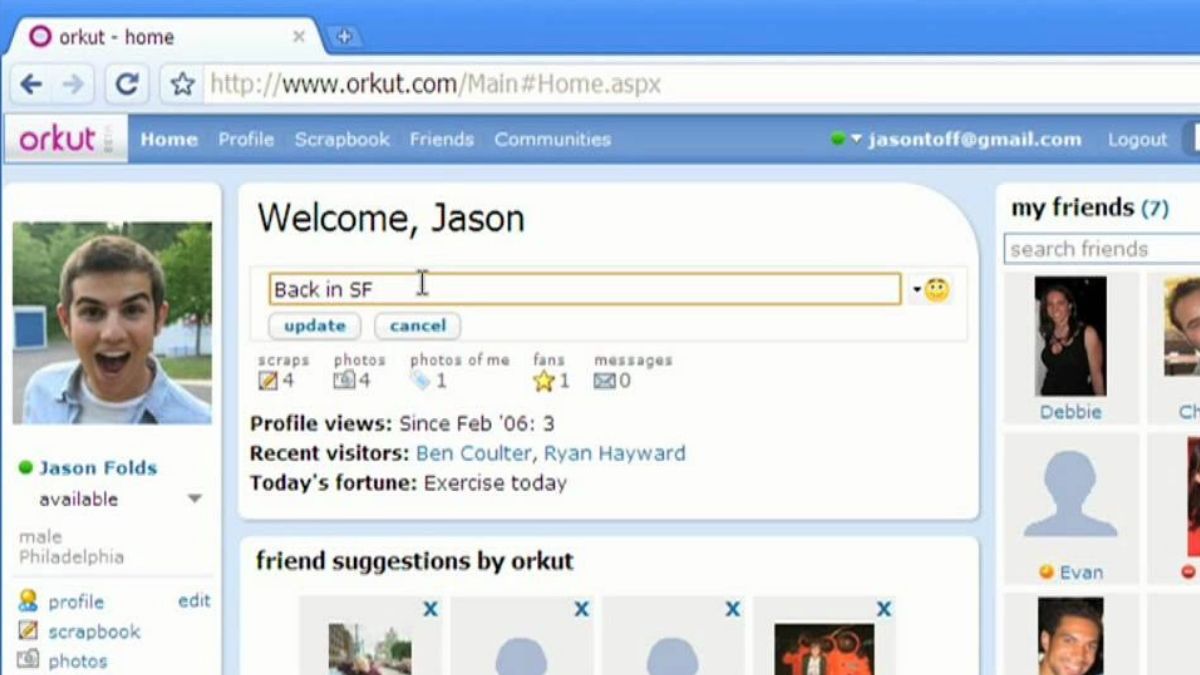
Orkut occupied a singular position in the cultural and emotional landscape of Brazil’s early internet. Between 2004 and 2014, its communities functioned as a semiotic infrastructure for online self-presentation. These user-created labels — “I love coffee,” “I hate waking up early,” or “Emo ♥” — operated as micro-utterances of identity, giving users a concise vocabulary for signaling taste, humor, relationality, and subcultural belonging.
Unlike contemporary platforms organized around algorithmic feeds, Orkut centered on static self-curation. The communities displayed on a profile formed a public, durable archive of identity performance.
Key Insight
On Orkut, you chose what represented you. Nothing was inferred or ranked by an algorithm.
This makes Orkut an unusually rich lens on intentional self-presentation.
1.2 A Global Platform in Motion (2004–2014)
Orkut’s geographic center shifted dramatically over its lifespan. Originally dominated by US traffic, it became overwhelmingly Brazilian, with India emerging as a major secondary hub.
Orkut’s user base shifted from US-centric in 2004 to predominantly Brazilian by 2014, with India as a significant secondary market. These shifts matter because linguistic, cultural, and stylistic norms on Orkut were shaped by its user base (especially Brazil and India) leading to a platform with its own vernacular logic.
1.3 A Brief Timeline of Orkut
Orkut Timeline (2004–2014)
2004: Orkut launches; US-centric user base
2005: Rapid adoption in Brazil; Portuguese becomes dominant
2007: Orkut becomes #1 in Brazil and India
2010: Infrastructure migration; visible slowdown in innovation
2012: Platform neglect; reduced moderation and updates
2014: Orkut shuts down; only Wayback remnants survive
1.4 Platform Decline and Digital Amnesia
When Google shut the platform down, the social world it contained was almost entirely erased. According to Orkut’s final public metrics:
51 million communities
120 million discussion topics
Over one billion user interactions
Nearly all of this vanished.
The loss was the downstream effect of a long process of enshittification understood not as monetization but neglect. In Cory Doctorow’s PyCon US keynote, he argues that platforms deteriorate when incentives to maintain user-centered infrastructure collapse. This framing strongly informed the conceptual orientation of this project.
Orkut’s shutdown was the end point of that trajectory — a once-vibrant cultural space allowed to decay before ultimate removal.
1.5 What Survives and Why It Matters
What remains of Orkut exists only in fragmentary form, preserved across inconsistent, partial snapshots in the Wayback Machine. These remnants constitute a sparse but invaluable archive of vernacular digital culture, capturing expressive practices central to everyday sociability in Brazil, India, and much of the early-2000s Global South internet.
This project retrieves and interprets a subset of those traces: 124,988 surviving community names. Using Python-based computational methods, the analysis treats these names as sociolinguistic artifacts — small inscriptions of identity, humor, desire, complaint, fandom, and cultural belonging.
Interpretive caution
Clusters and patterns in this study reflect linguistic similarity among community names, not the behavior or beliefs of actual users.
By analyzing these traces, the project maps the expressive and semiotic textures of one of the most influential platforms in the history of Brazilian digital culture.
2. Methods: Recovering Orkut From the Wayback Machine
Reconstructing Orkut’s community landscape requires working inside a broken, partial, and heterogeneous archive. With Orkut’s servers permanently offline, no API exists and the only surviving materials are irregular HTML snapshots preserved by the Wayback Machine. These snapshots differ in structure, completeness, and navigability. Even the basic task of retrieving community names becomes a form of computational archaeology.
The dataset used here contains 124,988 community names. All rows are present and no values are missing, but this represents only a small fraction of the 51 million communities that once existed. The names themselves vary widely in length, language, spelling, elongation, punctuation, and symbolic play.
Before formal modeling, I examined the raw CSV manually by searching cities, celebrities, fandom tags, slang variants, and emotional expressions. This helped build intuition about the expressive range of the dataset and highlighted the limits of anecdotal exploration. To understand patterns at scale, a systematic and computational approach is required.
Reproducibility
All analyses were run in a single Quarto document using Python.
Setting freeze: auto and cache: true allows rapid re-rendering while preserving computational reproducibility.
The methods below have two goals:
Reconstruct a usable corpus from inconsistent archival material.
Enable sociolinguistic interpretation of large-scale vernacular text.
Ethical Data Sourcing
All data was collected exclusively from publicly accessible archived pages in the Wayback Machine.
No private user information was accessed or reconstructed.
2.1 Overview of the Scraping Pipeline
The scraper is designed to navigate an unstable archive rather than a clean API. Its purpose is to capture every community name visible in surviving snapshots while accounting for structural variation and missing content.
Pipeline Steps
Load archived HTML pages from the Wayback Machine.
Identify alphabetical index pages for A to Z community listings.
Traverse pagination links for each index section.
Extract community names using multiple HTML patterns.
Handle redirects, missing elements, truncated pages, and layout changes.
Store all collected names in CSV format for downstream NLP tasks.
Why fallback logic is necessary
Different snapshots use different HTML structures.
Some pages are only partially saved or corrupted.
Selectors that work in one year fail in another.
A resilient scraper must assume that structure varies from page to page.
2.2 The Scraper (BeautifulSoup plus defensive extraction)
Scraping Orkut requires treating the platform as a historical artifact. Its HTML structure degraded long before the final shutdown, and the Wayback Machine captured pages opportunistically rather than comprehensively. As a result, class names, tags, and containers shift across snapshots. Pagination may be missing or incomplete. Some pages contain only text fragments with no surrounding markup.
The scraper therefore uses a layered extraction strategy:
Extraction Strategy
Begin with the most specific CSS selectors for intact pages.
If these fail, fall back to looser structural patterns.
If needed, fall back again to regular expression searches for text that resembles community names.
Continue until all reasonable interpretations of the page have been tested.
This approach reframes the scraping task:
Reconstructing an incomplete sociotechnical artifact
The scraper is not simply collecting data.
It is reconstructing a fragmented digital structure and making its surviving components legible for analysis.
Code
import requestsfrom bs4 import BeautifulSoupimport timeimport csvfrom urllib.parse import urljoin, urlparseclass OrkutCommunityScraper:def__init__(self, base_url):self.base_url = base_urlself.session = requests.Session()self.session.headers.update({'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' })self.communities = []def get_page(self, url):try: response =self.session.get(url, timeout=10) response.raise_for_status()return responseexcept requests.RequestException as e:print(f"Error fetching {url}: {e}")returnNonedef extract_communities_from_page(self, soup): communities = [] community_links = soup.find_all('a', class_='typoSectionTitleFont')for link in community_links: name = link.get_text(strip=True)if name andlen(name) >2: communities.append(name)ifnot communities: container = soup.find('div', class_='listCommunityContainer')if container:for link in container.find_all('a'):if'paginationSeparator'in link.get('class', []):continue name = link.get_text(strip=True)if name andlen(name) >2and name notin ['next >', '< previous', 'first', 'last']: communities.append(name)ifnot communities: selectors = ['a[href*="Community"]','a[href*="community"]','.community-name','.community-title','a[title*="community"]','a[title*="Community"]' ]for sel in selectors:for el in soup.select(sel): name = el.get_text(strip=True)if name andlen(name) >2: communities.append(name)returnlist(set(communities))def find_index_letter_links(self, soup): links = [] container = soup.find('div', class_='indexLettersContainer')if container:for link in container.find_all('a', class_='indexLetters'): href = link.get('href')if href: links.append(urljoin(self.base_url, href))return linksdef find_pagination_links(self, soup): links = []for link in soup.find_all('a', class_='paginationSeparator'): href = link.get('href')if href and'next'in link.get_text().lower(): links.append(urljoin(self.base_url, href))return linksdef scrape_letter_page(self, letter_url, letter): page =1 current = letter_url collected = []while current:print(f" Scraping {letter} - page {page}: {current}") response =self.get_page(current)ifnot response:break soup = BeautifulSoup(response.content, "html.parser") found =self.extract_communities_from_page(soup) collected.extend(found)print(f" Found {len(found)} communities on this page") next_links =self.find_pagination_links(soup) current = next_links[0] if next_links elseNone page +=1 time.sleep(1)if page >50:print(f" Page limit reached for {letter}")breakreturn collecteddef scrape_communities(self):print(f"Starting to scrape communities from: {self.base_url}") response =self.get_page(self.base_url)ifnot response:print("Could not fetch main page.")return soup = BeautifulSoup(response.content, "html.parser") index_links =self.find_index_letter_links(soup)print(f"Found {len(index_links)} index letter links.")ifnot index_links:print("Falling back to main-page extraction…")self.communities =self.extract_communities_from_page(soup)print(f"Found {len(self.communities)} communities.")returnfor i, link inenumerate(index_links): letter = link.split("l-")[-1].split(".")[0] if"l-"in link elsef"page_{i+1}"print(f"\nScraping letter {letter} ({i+1}/{len(index_links)})") collected =self.scrape_letter_page(link, letter)self.communities.extend(collected)print(f"Total for letter {letter}: {len(collected)}") time.sleep(2)self.communities = [c for c inset(self.communities) iflen(c.strip()) >2]print(f"\nTotal unique communities: {len(self.communities)}")def save_to_csv(self, filename="orkut_communities.csv"):withopen(filename, 'w', newline='', encoding='utf-8') as f: w = csv.writer(f) w.writerow(["Community Name"])for c insorted(self.communities): w.writerow([c])print(f"Saved to {filename}")def print_communities(self):for i, c inenumerate(sorted(self.communities), 1):print(f"{i:3d}. {c}")def main(): url ="https://web.archive.org/web/20141001005309/http://orkut.google.com/" scraper = OrkutCommunityScraper(url) scraper.scrape_communities() scraper.print_communities() scraper.save_to_csv()print(f"\nScraping completed: {len(scraper.communities)} unique communities found.")'''if __name__ == "__main__": main()'''
3. Linguistic Foundations: The Pre-Algorithmic Web
Orkut represents a largely forgotten layer of early social computing, a period before automated recommendation systems and behavioral prediction became central to online life. In this environment, identity was not shaped by algorithmic curation but by declarative self-presentation. Users selected and displayed communities as a way of signaling humor, taste, sentiment, and social belonging, producing a publicly visible catalogue of micro-identities.
The surviving community names function today as small ethnographic artifacts. They condense linguistic practices, cultural references, and forms of self-description that were meaningful within that historical moment. By analyzing these names at scale, the project reconstructs a semantic and stylistic landscape that reflects how users articulated personhood, affiliation, and emotion on a platform that relied on intentional curation rather than automated personalization.
4. Stylometric + Semantic Feature Engineering
Each community name carries both a style and a meaning. Stylometry measures how people wrote, while semantic embeddings model what they meant. Together, these features allow the analysis to map the linguistic diversity of Orkut at scale.
Code
csv_path ="orkut_communities.csv"df = pd.read_csv(csv_path)def extract_stylometry(text):ifnotisinstance(text, str): return pd.Series([0]*7) char_len =len(text) caps_ratio =sum(1for c in text if c.isupper()) / char_len if char_len else0 vowel_elong =len(re.findall(r'([aeiou])\1{2,}', text.lower())) punct_elong =len(re.findall(r'[!?.]{2,}', text)) has_k =1if'k'in text.lower() andnotany(x in text.lower() for x in ['rock','ok','park','link','work','black','dark','york','hack','check']) else0 symbol_density =len(re.findall(r'[^a-zA-Z0-9\s.,?!]', text)) / char_len if char_len else0return pd.Series([ char_len,len(text.split()), caps_ratio, vowel_elong, punct_elong, has_k, symbol_density ])feat_cols = ["n_char","n_word","caps_ratio","vowel_elong","punct_elong","k_style","sym_density"]df[feat_cols] = df["Community Name"].apply(extract_stylometry)def clean_text(x): x =str(x) x = unicodedata.normalize("NFKC", x) x = re.sub(r"&[a-z]+;", "", x)return x.strip().lower()df["cleaned"] = df["Community Name"].apply(clean_text)
Methodological note on k_style feature
Limitations of the k_style feature are discussed below.
5. Language Detection
This step provides a high-level view of the multilingual landscape of Orkut’s communities. Almost all names are in Portuguese, reflecting Orkut’s predominance in Brazil, followed by English and Spanish, and then smaller clusters in Italian, Catalan, French, Somali, Indonesian, Romanian, Welsh, Tagalog, and Swedish. The distribution confirms that the dataset is culturally anchored yet globally porous, with enough linguistic variation to shape downstream clustering and topic formation.
To explore the latent structure of Orkut’s community names, each name is converted into a dense vector using multilingual sentence embeddings. These vectors capture semantic and stylistic similarity, allowing names with related themes to appear close together even when they share no vocabulary. UMAP is then used to reduce the high-dimensional embedding space into two dimensions for visualization, and KMeans provides coarse clusters that highlight broad thematic regions.
The UMAP plot below represents this semantic landscape. Each point corresponds to a single community name, and colors indicate cluster assignments. Although the plot is a compressed view of a richer embedding space, several sociologically meaningful patterns emerge. Dense regions reflect shared vocabularies and shared social worlds such as school life, humor, fandom, religion, emotional expression, and vernacular identity categories. Sparse areas often represent niche subcultures or idiosyncratic naming styles.
Reading UMAP Distances
UMAP preserves local neighborhoods but distorts global distances. Clusters should be read as regions of relative similarity, not literal separations between social groups.
Taken together, the map shows how early social networking users collectively organized meaning through simple acts of naming. Community titles worked as micro-utterances of identity, affiliation, and emotion. The UMAP projection makes this structure visible, revealing a continuous semantic field rather than isolated categories. It is a linguistic geography of the pre-algorithmic web.
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers` before the fork if possible
- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)
7. Stylometric Topography
Why Stylometry?
Stylometric features (like capitalization, elongation, or symbolic play) help detect how people expressed themselves, complementing embeddings that capture what they meant.
The two maps in this section project stylometric features onto the same UMAP space introduced earlier. The x and y axes come from UMAP and represent low-dimensional coordinates that preserve neighborhood structure. Points that lie close together correspond to community names with similar meanings in the multilingual embedding space.
7.1 Caps Lock Intensity
For the caps lock intensity map, each point is colored by the proportion of uppercase characters in the community name (caps_ratio). This feature acts as a loose proxy for visual intensity or emphasis.
The global pattern looks diffuse, but small pockets of darker points can appear on closer inspection. These pockets represent localized concentrations of high caps ratios rather than an even spread. When they occur, they often align with semantic regions where community names express strong affect, playful antagonism, or exaggerated humor.
Interpretive caution on caps_ratio
Caps usage is not a reliable emotional signal on its own. It should be understood as one stylistic feature that may cluster weakly with certain genres, not as evidence of genuine sentiment.
Because the analysis works only with community titles, the map cannot show why users chose these orthographic styles. What it can show is that capitalization is not entirely random. It tends to appear in specific stylistic neighborhoods, suggesting mild but detectable structure in how Orkut users used visual emphasis.
Miguxês is a playful, youth-oriented online writing style that became widespread in Brazil during the early 2000s and was especially visible on Orkut. It uses deliberate spelling changes, including the replacement of qu with k, to signal informality, intimacy, and membership in specific online peer cultures.
The miguxês map colors each point using a binary indicator (k_style) that marks names where the letter k appears in positions where standard Portuguese uses qu, as in kerer or kasa. Clear English words such as rock or link were filtered out so that the feature would more reliably capture Portuguese stylistic play. This indicator captures only one dimension of miguxês and should be understood as a narrow and approximate proxy.
Methodological note on k_style
The k_style feature is a narrow heuristic meant to approximate one aspect of miguxês. It carries a high risk of false positives because many languages and proper nouns use the letter “k” naturally. It should therefore be treated only as a coarse stylistic proxy, not a reliable classifier of miguxês.
Even with this limited feature, the map shows localized clusters of stylistically marked names rather than a uniform distribution. These clusters often fall in semantic neighborhoods associated with youth-oriented or playful communities, which aligns with sociolinguistic descriptions of miguxês as a register tied to online peer groups.
The overall pattern suggests that orthographic style participated in the same latent structure as topic, sentiment, and language. Spelling choices were one of the ways Orkut users signaled identity and social alignment in public.
BERTopic handles short, multilingual, and stylistically varied text by using contextual embeddings rather than bag-of-words. Its HDBSCAN clustering discovers topics without predefining their number, and c-TF-IDF makes the resulting clusters interpretable. This makes it well-suited for exploratory analysis of Orkut’s heterogeneous community names.
BERTopic allows us to derive “micro-communities” of meaning directly from the community names. The algorithm embeds each name into a multilingual semantic space and then groups them using density-based clustering. These clusters are not meant to represent discrete cultural categories but rather local neighborhoods of shared lexical and thematic similarity. They reveal the fine-grained structure of Orkut’s collective self-presentation and help identify pockets of humor, affect, fandom, everyday life, and regional identity that would be difficult to isolate by manual inspection alone.
Topic
Count
Name
Representation
Representative_Docs
0
-1
39405
-1_você_vc_me_que
[você, vc, me, que, pra, the, quem, se, vai, oficial]
[quero mais é que ele(a) c foda, por seu amor faço tudo! ♥, se eu odeio minha mãe ?]
The BERTopic model identifies recurring patterns in how Orkut users named their communities. These topics are not communities of people but clusters of titles that share similar lexical and semantic properties. They help reveal the cultural motifs, expressive habits, and identity markers that shaped the platform’s public vocabulary. The following subsections introduce the main diagnostic plots used to interpret these patterns and discuss what they suggest about the structure of Orkut’s naming conventions.
8.1.1 Topic Barcharts (Top 20)
The charts below display the highest-scoring words for the twenty most prominent BERTopic micro-communities. Each topic represents a dense lexical neighborhood in embedding space. These are not “real” communities in the sociological sense but statistical clusters formed from surface cues in community names. Their value lies in revealing the recurring motifs through which Orkut users signaled identity, affinity, and humor.
In aggregate, these twenty topics illustrate the semantic texture of Orkut’s community names. They suggest that self-presentation was shaped by nationality, affect, fandom, kinship, humor, and everyday evaluations. Because the analysis operates only on community titles, these clusters should be read as patterns of linguistic association rather than strict categories of online social life.
8.1.2 Intertopic Distance Map
The intertopic distance map projects all micro-topics into a two-dimensional embedding space. Each circle represents a topic, and circle size corresponds to its relative frequency. Topics that appear close together share similar semantic environments. Topics that appear far apart occupy distinct regions of the expressive landscape. The map shows that the naming practices on Orkut formed several clusters of related meanings rather than a single homogeneous field. It also reflects the high granularity of the model, since hundreds of micro-topics coexist within a relatively dense space.
The dendrogram arranges topics into a hierarchical structure based on similarity. Although visually extensive, it provides a valuable multi-scale view of the landscape. Small micro-topics join into medium clusters, and medium clusters join into larger families. This structure shows that users relied on a repertoire of related naming styles that blend into one another at higher levels of abstraction. The dendrogram should not be interpreted as a taxonomy of social categories. Instead it helps reveal how diverse micro-styles combine to form broader semantic regions.
The term-score decline plot shows how sharply c-TF-IDF values fall within each topic. For most topics, the top-ranked word is far more distinctive than the words that follow. This pattern indicates that many topics have a narrow lexical core that strongly defines them. A minority of topics display flatter curves, suggesting more heterogeneous naming patterns. The overall impression is that Orkut community names often relied on formulaic and highly concentrated lexical signals. Users did not draw from an unlimited vocabulary but instead repeated familiar patterns that the model can easily detect.
The similarity matrix compares the twenty largest topics and displays cosine similarity among their embeddings. Darker squares correspond to higher similarity. Clusters associated with affection vocabulary appear near each other. Clusters that emphasize national identity or family categories also align closely. In contrast, topics tied to early internet slang, rock music, fan scenes, or personal names occupy more distant positions. This matrix supports the interpretation that Orkut naming practices were structured by a small number of expressive families rather than a random assortment of unrelated phrases.
Herein, we develop a summarize_topic function based on abstracted linguistic patterns rather than raw community names. The summaries draw on the cluster’s top keywords to generate representative expressions, such as positive and negative stance formulas, fandom markers, or nationality labels.
The goal is to give an interpretable sense of what each topic captures without exposing individual community titles (which can be inappropriate). This pattern-based approach supports a sociological reading of the clusters by foregrounding recurrent forms of stance, affiliation, and identity work, while minimizing the noise and volatility of the original community names.
Code
def summarize_topic(topic_id, n_patterns=5):""" Summarize a BERTopic micro-cluster using: - Top keywords - Interpretable synthetic linguistic patterns - Cluster size Without printing any real community names. """print("="*90)print(f"TOPIC {topic_id}") topic_words = topic_model.get_topic(topic_id)ifnot topic_words:print("(No keywords, likely outlier cluster)")return# -----------------------------# 1. Show top lexical signals# -----------------------------print("\nTop Keywords:")for w, weight in topic_words[:10]:print(f" • {w} ({weight:.3f})")# -----------------------------# 2. Show cluster size# ----------------------------- size = (df["topic_micro"] == topic_id).sum()print(f"\nCluster size: {size}")# -----------------------------# 3. Generate synthetic examples# -----------------------------print("\nRepresentative Linguistic Patterns:")# extract top words only top_words = [w for w, _ in topic_words[:15]]# templates for positive affect positive_templates = ["eu amo {w}","eu adoro {w}","eu gosto de {w}" ]# templates for negative affect negative_templates = ["eu odeio {w}","eu nao suporto {w}","eu nao gosto de {w}" ]# templates for identity / belonging identity_templates = ["sou fã de {w}","grupo dos que gostam de {w}","pessoas que apreciam {w}" ]# templates for fandom / pop culture fandom_templates = ["fãs de {w}","eu assisto {w}","eu admiro {w}" ]# templates for general noun clusters generic_templates = ["coisas relacionadas a {w}","pessoas interessadas em {w}","comunidade sobre {w}" ]# heuristics based on keywords patterns = []ifany(w in ["amo", "gosto", "amor", "adoro"] for w in top_words):for t in positive_templates: w = top_words[0] patterns.append(t.format(w=w))ifany(w in ["odeio", "raiva", "insuportável"] for w in top_words):for t in negative_templates: w = top_words[0] patterns.append(t.format(w=w))ifany(w in ["brasil", "india", "familia", "universidade"] for w in top_words):for t in identity_templates: w = top_words[0] patterns.append(t.format(w=w))ifany(w in ["rock", "anime", "msn", "musica"] for w in top_words):for t in fandom_templates: w = top_words[0] patterns.append(t.format(w=w))# fallback if nothing matchesifnot patterns:for t in generic_templates: w = top_words[0] patterns.append(t.format(w=w))# print only n_patternsfor p in patterns[:n_patterns]:print(f" → {p}")
9. Sentiment Mapping
The plot below colors each community name by its VADER compound sentiment score. Because titles are short and often elliptical, the sentiment model captures only coarse emotional valence, but meaningful structure still appears when the scores are projected into the same UMAP space used earlier.
A small and dense pocket of blue points emerges in the map. One plausible explanation is that positive expressions in Portuguese are highly formulaic, relying on a narrow set of verbs and constructions such as amo, adoro, and gosto muito. These forms share similar lexical and syntactic shapes, which causes their embeddings to cluster tightly.
Negative sentiment, by contrast, tends to be more syntactically varied and often built from negation such as odeio, detesto, não gosto, and não suporto. Negation introduces structural diversity, which spreads negative expressions across a wider region of the embedding space. The result is a relatively compact region of positive sentiment and a more diffuse cloud of negative sentiment.
These patterns should not be interpreted as psychological claims about Orkut users. They reflect linguistic regularities in how positive and negative stances are expressed in short text. Even at the level of brief community titles, sentiment appears to align with distinct stylistic micro-registers, revealing another dimension of how Orkut users performed identity and emotion.
VADER is designed for English and does not model Portuguese morphology, syntax, or diacritics. It produces scores for Portuguese titles only when they contain English loanwords, punctuation cues, or affective markers that overlap with its lexicon. As a result, the sentiment values here should be interpreted strictly as a coarse heuristic rather than a valid measure of sentiment in Brazilian Portuguese. Any stronger claims would require a sentiment model trained specifically on Portuguese data.
10. Conclusion: The Vernacular Archive
This study treats Orkut not as a failed experiment in social networking but as a vernacular archive that preserves the informal, playful, and affective practices of an early social web. The data recovered here show how millions of users produced a shared grammar of self-presentation through short, declarative community names. These titles formed a lightweight infrastructure of identity that blended humor, sentiment, subcultural affiliation, and everyday social commentary.
Across embeddings, stylometry, and topic models, a coherent picture emerges. Users drew on nationality, kinship, fandom, youth registers, emotional stance, and linguistic play to situate themselves within a broader cultural landscape. The resulting clusters are not communities in the sociological sense but traces of the associative logics through which people oriented themselves to others in public.
As contemporary platforms move toward feeds shaped by algorithmic curation and AI-generated content, Orkut’s remnants highlight a different moment in the history of digital culture. What survives in these archived pages is a form of expression that was concise, user driven, and intensely local to its era. These fragments matter because they document how ordinary users once crafted identity and belonging online, and because they remind us that large-scale digital environments can hold cultural value long after their commercial life ends.
11. Future Directions
This project analyzes only community titles, yet the surviving Orkut archive contains additional material that can support deeper data science and sociological inquiry. Several realistic extensions are possible:
Richer sociolinguistic feature engineering.
Community names contain elongations, symbolic characters, mixed languages, playful spellings, and youth-coded forms. Building more targeted features for these patterns could sharpen analyses of stylistic variation across the semantic space.
Geographic and identity markers.
Many community titles reference cities, regions, nationalities, or diasporic identifiers. Extracting and normalizing these terms would enable studies of how place-based identity was expressed and how it clustered semantically.
Lexical field and register mapping.
By expanding the feature set beyond embeddings and stylometry, one could map specific registers (affection, complaint, aspiration, humor, fandom) and compare how they co-locate within the UMAP space.
Forum-level micro-analysis.
Some archived communities still contain partial forum threads. Even small samples could support qualitative or hybrid analyses of conversation styles, humor norms, and identity performance. This project did not examine forum content, but the material is accessible for researchers who want to study actual interactional behavior rather than only titles.
Minimal structural reconstruction.
A subset of archived pages includes related-community links or membership counts. Although incomplete, these fragments could support exploratory attempts to reconstruct small-scale community networks or affinity clusters.
Cross-feature alignment.
Combining embeddings with stylometric indicators (caps usage, elongation, symbolic density, language) may reveal how expressive practices correspond to semantic neighborhoods. This would deepen the understanding of how linguistic style functions as a marker of online identity.
These directions invite data scientists and sociologists to treat Orkut’s remnants as a compact but analytically rich archive. The surviving traces support meaningful inquiry into how people encoded identity, emotion, and belonging in one of the earliest large-scale social platforms.
12. References
Conneau, A., Khandelwal, K., Goyal, N., et al. (2020). Unsupervised Cross-lingual Representation Learning at Scale (XLM-R). Proceedings of ACL 2020. https://doi.org/10.18653/v1/2020.acl-main.747
Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of NAACL 2019. https://doi.org/10.18653/v1/N19-1423
Hutto, C., & Gilbert, E. (2014). VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. Proceedings of ICWSM 2014. https://doi.org/10.1609/icwsm.v8i1.14550
McInnes, L., Healy, J., & Astels, S. (2017). hdbscan: Hierarchical density based clustering. Journal of Open Source Software, 2(11), 205. https://doi.org/10.21105/joss.00205
McInnes, L., Healy, J., & Melville, J. (2018). UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction.https://doi.org/10.48550/arXiv.1802.03426
Open-source Python ecosystem:BeautifulSoup, UMAP, BERTopic, SentenceTransformers, Plotly, and related libraries that made scraping, modeling, and visualization possible.
Posit open-source ecosystem:
Positron IDE, whose Data Explorer and integrated environment supported rapid inspection and iteration.
Quarto, which enabled reproducible analysis and seamless rendering of this document.
Data science and sociotechnical research communities: Their shared methods, tools, and public discussions informed the conceptual framing of this work.
14. Contact Information
For questions or collaboration opportunities, feel free to reach out: